Dynimize: The Big Picture
In a nutshell, the purpose of Dynimize is to help further the progress of general purpose computing performance. This progress has provided society with a steady stream of new computing applications that have helped us in myriad ways. Greater performance allows for more complex computing tasks, increasing the usefulness of software across all domains. Over the past ten years, the rate of improvement has been significantly reduced in several ways. The mission of Dynimize is to contribute towards the continuation of this progress through the development of CPU performance virtualization.
How is progress in processor performance made?
For the remainder of this post, we interchange the terms CPU (central processing unit), processor, and microprocessor, even though the true definitions may differ slightly.
Machine instructions are the building blocks of all software. A computer program can be seen as a composition of machine instructions and data, with the instructions representing the thought process of a program. Each instruction implements a primitive operation for a computer to perform, and is executed by the system's one or more microprocessors. A microprocessor executes instructions in accordance with a schedule that is dictated by an internal clock, and each instruction typically takes one or several clock ticks or cycles to execute. The faster the clock operates, the shorter each cycle, and the less time each machine instruction requires to perform its task. The net result of a faster clock is that software takes less time to perform a specific job. However, this clock cannot be set at an arbitrarily high frequency. The faster it's set, the less time each component has to complete its task. If this time is insufficient, the microprocessor will not function correctly.
Frequency Scaling
Microprocessors are comprised of transistors, which are switches that implement the operations of each machine instruction. The speed at which the system clock can operate is dictated by how quickly these transistors can change state. The steady progress of semiconductor manufacturing over the years has continuously shrunk the size of transistors, which in-turn has allowed them to change state more quickly. This has resulted in the setting of faster clock speeds, or higher frequencies, which has produced shorter operating times for each machine instruction, creating faster, more capable computers. The effect of frequency on performance can be described by the following equation:
Runtime = (Instructions/Program) x (Cycles/Instructions) x (Time/Cycle)
where instructions per program is the total number of instructions executed in a given program, cycles per instruction is the average number of clock cycles required to execute each instruction, and time per cycle is the inverse of frequency. Note that this does not include time spent reading or writing to persistent storage such a hard drive (known as I/O time) or time spent waiting for network operations to complete. However, from the above model we can see that increasing frequency (reducing time/cycle) will reduce a program's runtime, thereby increasing performance.
The pace of progress in semiconductor manufacturing has allowed transistors to shrink in half every two years, resulting in increases in processor frequency, and the following graph illustrates how processor frequency has progressed over the decades. This graph was taken from the Standford VLSI Group's CPU DB:
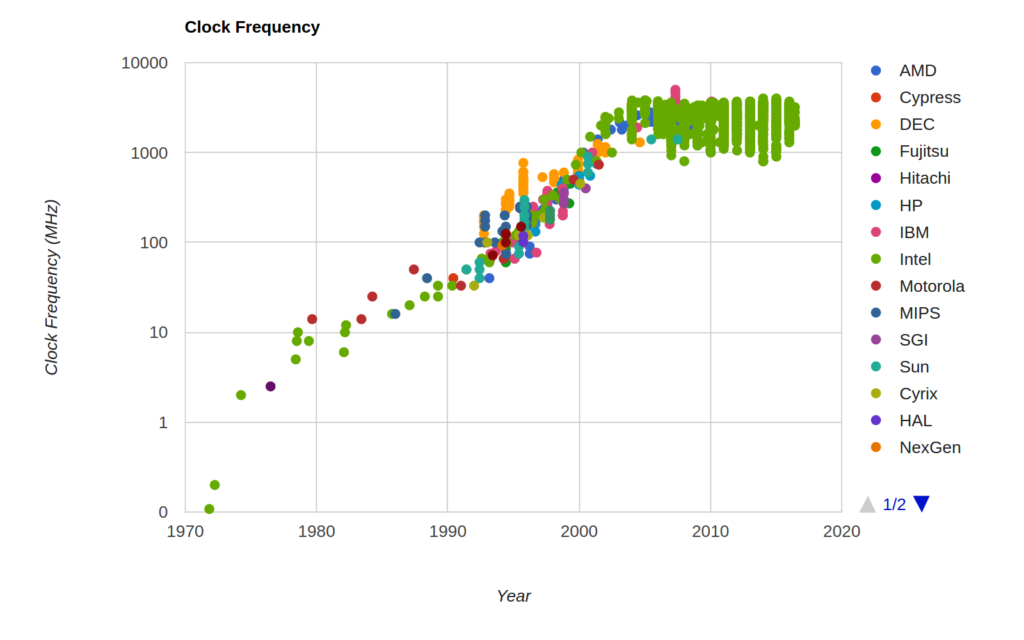
This increase in frequency has come with a major side-effect. Each time a transistor switches from one state to another, it dissipates energy in the form of heat. The general equation for processor power is as follows:
Where C is the total capacitance being switched per clock cycle, V is voltage, and F is processor frequency. Note that this power consumed is mostly dissipated as heat. As clock speeds increased over the years, so did the speed at which these transistors changed state, along with their rate of heat production. Eventually the thermal limits of frequency scaling were reached when in 2004, Intel cancelled its next generation higher frequency processors to pursue a multi-core approach to increase performance going forward. This marked the end of frequency scaling as the overriding methodology for improving general purpose computing performance, and the rest of the industry followed suit. You can see this in the above graph where CPU frequency eventually plateaued around 2004, and we've been stuck in the range of 1-4 GHz ever since.
Frequency Scaling is Dead:
Improving Performance Without it
Increasing IPC
From the original runtime equation above, we can see that there are two other ways to improve processor performance. One of them is to reduce cycles/instruction. The inverse of this is called IPC (instructions per cycle), and increasing IPC has therefore become one of the major overarching goals of each new generation of microprocessors. However, increasing IPC is challenging and each jump in improvement has required a complete redesign of the processor microarchitecture. Over the past decade, Intel has managed to release a new microarchitecture design roughly every two years, each one increasing IPC by an average of approximately 10%. Below is a graph estimating the changes in IPC over 12 years of progressive Intel processor designs (code names on the bottom axis), courtesy of Rob Farber.
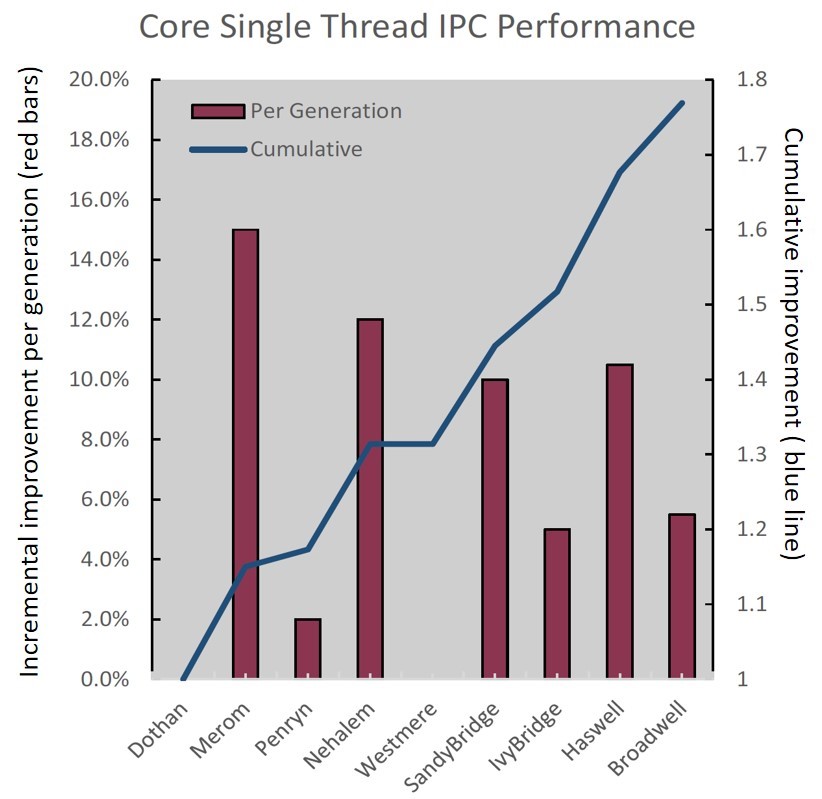
Increasing IPC is highly valuable because already existing software does not have to be rebuilt or modified in any way to take advantage of these improvements. This is similar to how previous increases in frequency would benefit most workloads. Since the largest investment of most IT system's is in its software, being able to experience performance improvements by simply moving from one hardware system to another is highly valuable, and for years has been the cornerstone of the computer industry's value proposition for upgrading hardware. The downside is that IPC improvements occur very gradually, as illustrated by the previous graph.
Increasing Cores
Aside from increasing IPC, the other major technique CPU architects have been using is to encapsulate much of the functionality of a CPU into a unit called a core, and introducing designs with multiple cores. Because transistors have continued to shrink since the end of frequency scaling, designers have been able to pack more of them onto a single chip, and increasing cores has been one way to use these excess transistors. With multiple cores, a processor can execute the instruction streams of multiple programs at the same time.
On an abstract level, the operations of a sequence of many machine instructions combine into higher level tasks known as algorithms. Breaking down an algorithm into smaller components that can be run at the same time on separate cores is known as parallelization, and allows for the overall algorithm to progress more quickly. Writing software that exploits multiple cores is very challenging, and the underlying algorithms of many applications cannot be parallelized. For example, if a particular step in an algorithm relies on a result produced by a previous step, both steps cannot be run at the same time in parallel. This is called a data dependency, and many of these exist in all software to some extent. Applications such as computer graphics and the neural networks used in artificial intelligence are easy to parallelize, however most applications are not due to these data dependencies, and are therefore only able to utilise one or a few cores at most. Unlike the case with IPC or frequency scaling, where software can exploit these improvement without making any changes, software usually has to be rewritten to exploit multi-core processors, or even scale from older processors with a few cores to newer designs with many cores. That is expensive and in many cases not possible due to the data dependencies that exists in a program's algorithms.
The Challenge
With the increase in IPC happening at a very gradual pace, and multi-core processors difficult to exploit, the performance of many areas of computing have progressed at a slower rate in recent years. This problem may very well continue going forward.
To be honest, these trends make me kind of sad. As a kid I was always thrilled every time Intel would release a new CPU that made the latest one that was a few months old completely obsolete. I was excited to see all the new computing applications crop up that weren't really feasible a year before. Today we only truly experience that in the GPU world with highly parallel workloads like computer graphics and AI. Of course those applications are extremely valuable, but there are far more applications that can't easily be parallelized and haven't come into existence yet because of this sequential computing plateau that we've hit. I'd like to see a future where these new applications exist, or come to us sooner rather than later, and where our current applications progress at a faster pace.
Enter CPU Performance Virtualization
Wouldn't it be nice if we could have an invisible software layer that gives the illusion of running your workload on a more powerful processor? Let's revisit the original performance equation:
Runtime = (Instructions/Program) x (Cycles/Instructions) x (Time/Cycle)
The first component (Instructions/Program) is completely dependant on the software being run, while the second component (Cycles/Instructions) is highly influenced by it. In theory, a software layer that has the ability to alter the machine instructions of running programs could potentially reduce the value of both components, thereby increasing performance. If this software layer could be designed in such a way that it was invisible to the end user, where programs would not have to be modified in any way to exploit it, then we could argue that this layer is in a sense emulating the effects of increased processor performance. Hence the term CPU performance virtualization or CPV. The following are three important methods CPV could use to accomplish this.
1. CPV by Reducing Cycles/Instruction (Increasing IPC)
Subsequent microprocessor designs have increased IPC by improving their internal architecture (microarchitecture). They do this by adding hardware implementations of advanced techniques such as branch prediction, instruction and data cache prefetching, and out-of-order instruction execution, to name a few. Along with the microarchitecture, IPC is highly dependant on the machine instructions used to implement a program. Just like there are endless ways to solve the same math problem, two programs or algorithms could perform the same task in theory, but in practice be comprised of very different machine instructions, and have higher levels of IPC in one implementation over another. For this reason, many of the problems solved by the above mentioned microarchitecture techniques could also be solved by implementing a software program with more optimal machine instruction sequences. The following illustrates an example.
If we are able to rearrange the order of some machine instructions in a program without violating data dependencies and maintaining the same functionality (a technique known as instruction scheduling), we could potentially alter the number of CPU cycles required by those instructions to execute. Imagine a processor that has a specific resource that can be monopolised by an instruction, with two instructions that are executed back to back both needing that same internal resource. With the first instruction monopolising that resource for several cycles, the second instruction is forced to wait several CPU clock cycles for the first instruction to complete and release that resource before it can begin execution. However, if later instructions that do not require that resource can be scheduled to execute right after the first instruction, they won't have to wait for that resource and can make use of the processor while the original second instruction is waiting for that resource. Because those inserted instructions will ultimately have to be executed eventually, and were now executed during a time that would have otherwise gone to waste, the overall runtime of the program has been reduced, and the average number of instructions per clock cycle (IPC) has gone up. This software technique is know as instruction scheduling, however it can also be performed in hardware by a technique known as out-of-order execution where the processor automatically finds instructions to execute during wasted cycles. The advantage of doing this in software is that the program that generated the machine code, know as a compiler, can do this using very sophisticated scheduling techniques. However one downside of doing this in software is that the instruction sequences are generated without knowing the specific processor model of each end user, and so the resources available and other timing details are unknown. Additionally, the compiler may not have been able to predict the most likely instruction sequences a program will execute, information used by a scheduler to make better decisions. For these reasons, there are many benefits to doing this in hardware since a processor's out-of-order execution engine has access to this information. However, being implemented in hardware greatly limits the complexity of the scheduling techniques that can be used.
If we continue with the scheduling analogy, a CPV agent that performs software instruction scheduling at run-time could emulate a processor's out-of-order execution engine while having access to similar run-time information that the processor has, and utilise more complex software scheduling algorithms, thereby improving performance beyond out-of-order execution alone. In this sense, CPV could be seen as emulating a more powerful CPU microarchitecture.
2. CPV by Reducing Instructions/Program
The best way to illustrate this is also with an example, and for that we'll use the method inlining compiler optimization. At one level of abstraction, a program's machine instructions are arranged into units called subroutines or methods. These subroutines can take in data as input, operate on that data by executing machine instructions, and can then return a result. A subroutine may be invoked in many places in a program's machine instructions wherever the program requires the functionality of that subroutine, thereby allowing for code (machine instruction) reuse. The benefit here is that code is reused and a program is therefore smaller, which can help performance, and make the code easier to manage by its developers. The downside is that the subroutine must be general purpose enough to handle all invocations at different points in a program, which requires the subroutine to utilise more machine instructions than necessary to perform a specific task. A compiler could overcome this by replacing each subroutine invocation with a copy of that subroutine, tailored just for that specific invocation. The downside is that if we do this everywhere, the program will be much larger, which could potentially hurt performance for various reasons. However, at run-time CPV could perform the same task more selectively, only doing this for the parts of the program that are executed most frequently, as opposed to the entire program. It could do this at run-time because it can observe which paths through a program are executed more frequently while a program is running and only inline subroutine invocations on those "hot" paths. That would allow CPV to tailor only the most performance critical subroutine invocations, while marginally increasing the original program size. This would produce most of the benefit with fewer side effects, making this optimization much more profitable overall.
3. CPV by Auto-Parallelization
Earlier on we talked about multi-core processors and the challenge of parallelizing programs to exploit them. At run-time, CPV could in theory parallelize programs allowing software to better exploit newer processors with more cores. By doing this at run-time, CPV can collect statistics about potential data dependencies in a program and more aggressively try to parallelize a program than a traditional compiler.
Dynimize as a CPV layer
Dynimize Beta acts as a CPV layer, where most of the gains are currently performed by increasing IPC (method 1 above). In one sense you can look at it as an extension of the CPU microarchitecture, implemented in software. The optimizations used in the current release reduce instruction cache misses, branch prediction misses and ITLB misses, and therefore emulate the existence of a larger instruction cache, branch predictor, and ITLB respectively. These "misses" are stalls in the processor's pipeline that occur when waiting for instructions to enter the CPU, and are referred to as front-end CPU stalls. An instruction cache, branch predictor, and ITLB are components of the microarchitecture that help to reduce those stalls, and are limited resources within a microprocessor. The current version of Dynimize also performs some of the optimizations in (2), however those are more restricted at the moment. I believe future iterations of Dynimize will provide most of its speedup through (2), and eventually (3). As of now, Dynimize is not capable of auto-parallelization.
Putting Dynimize into Context
For applications that spend much of their time in front-end CPU stalls, Dynimize has been shown to increase IPC for MySQL (the world's most popular database for web infrastructure) by up to 60%, with an average of 30% across various benchmarks and processor generations. If we put this into the context of the microprocessor industry, where each generation improves IPC by an average of 10%, requiring hundreds of millions in investment for each new design, we could argue that the returns on effort by pursuing CPV are well worth it. Of course reducing front-end CPU stalls on MySQL and its related variants (MariaDB, and Percona Server) is not the same as speeding up all or most software, the way a new processor design would. However, the optimizations performed by Dynimize are general purpose, and Dynimize is only supporting these three applications at the moment in order to simplify the development effort for this release. Subsequent releases will support additional programs, and I believe that most performance critical programs will eventually benefit from Dynimize in the future. In the long run, we may even offer a default option of replacing the supported target list with a non-supported list, meaning that all software except a few listed programs will be potential Dynimize targets.
Why start with MySQL variants?
MySQL is commonly used to support OLTP workloads (online transaction processing). Beyond being performance critical and highly valuable to many organisations, OLTP workloads are characterised by a flat execution profile. This means that execution time is broadly distributed throughout the machine instructions of a program running an OLTP workload. For example, MySQL's execution profiles here often show every subroutine consuming less than one percent of the overall execution time. This means that in order for optimizations to be helpful, they must be broadly applicable in a general purpose manner, across much of the program in order to have any meaningful benefit. This prevents development time from being spent on optimizations that only show up in a few specifics, narrow cases, and allows Dynimize to speedup applications it's never looked at before, right out of the box. For example, although Dynimize does not yet support MongoDB, a highly popular NoSQL database, I've tried Dynimize with MongoDB and instantly got very similar speedups on MongoDB OLTP workloads (using Sysbench) even though no development work has ever been done to target MongoDB (or make Dynimize stable optimizing MongoDB for that matter!). So although I don't recommend using Dynimize Beta in production with non-MySQL targets, rest assured it is capable of speeding up many other applications, some of which will soon become officially supported. Of course MySQL is I/O-bound in many setups, meaning CPU performance is not critical in those instances, however there are still benefits to dynimizing I/O bound MySQL workloads such as freeing up CPU resources for other tasks, or reducing CPU power consumption.
Dynimize Going Forward
Dynimize Beta is just scratching the surface of what's possible with CPV, and the roadmap for Dynimize is quite long and ambitious. In general, each new release will include additions that provide the biggest impact for the largest market with the least development effort. Obvious candidates for the next release will include reducing the amount of memory, time, and CPU overhead incurred during the dynimizing phase (overheads incurred briefly early on when Dynimize optimizes a program). Adding official support for IBM DB2, or MongoDB could be done without too much development effort since their process architectures are similar to MySQL (single process, mostly user-mode execution). There's still some low-hanging fruit in reducing front-end CPU stalls, and it would be nice to capture the remainder of those opportunities. Supporting kernel-mode execution as an option would add additional speedup to the currently supported targets, and allow for new targets that spend most of their time in kernel mode execution such as NGINX, Redis, Memcached and some Apache HTTP Server workloads. Adding efficient support for multi-process workloads with processes that have short lifetimes could be the next obvious addition, and allow for full support of Apache HTTP server, Oracle Database, and Postgres, for example.
I believe most performance critical non-Java based infrastructure software on Linux would benefit from Dynimize by this point. If anyone provides us with valuable commercial workloads that are data cache bound, several powerful optimizations for that have already been prototyped in Dynimize (tested on SPEC CPU) and so adding support there would make a lot of sense. A Windows port seems like an obvious next choice, and would expand the user base and open the door to many consumer applications. From here on in, type 2 CPV optimizations would be emphasised in new releases, along with auto-parallelization and auto-vectorization. Front-end pipeline stalls are a major limitation for GPUs supporting more general purpose workloads, and so a GPU port of Dynimize could make a lot of sense at some point. If that works out well, we'd also explore partitioning machine instructions between CPUs and GPUs to support more parallelization and heterogeneous computing. This is a tall order, but I do believe it's all possible with the right effort, and would help provide most industries and consumers with easy access to higher levels of computing power.
David Yeager
David Yeager is the founder of Dynimize Inc, with over a decade of experience in just-in-time compiler development. He is passionate about computer architectures and software performance, and his mission is to see dynamic compilation and optimization accelerate all workloads (through Dynimize).